
Slides from ALPSP DRM Tech Update
Thursday, March 29, 2007
My talk, DRM: A Skeptic's View, as you can guess from the title was largely anti-DRM. I attempted to measure DRM against two yard-sticks: ability to enable new business models, and stopping unlicensed usage. My feeling is that DRM fails to achieve on either point. I feel strongly that publishers should be looking at ways to innovate and create new models for selling and licensing content, but that DRM isn't a necessary step to achieving that. I pointed to a few examples of what I think is innovative behaviour, e.g. Safari, Beta books, etc.
I found the talk from the British Library, outlining how they had deployed DRM for their Secure Electronic Delivery (SED) service, particularly compelling. Mat Pfleger clearly laid out some of the hidden costs of DRM that they encountered, particularly the increase in user support and the time it took to actually get clients up and running with the required versions of Acrobat. If you're thinking about implementing DRM you should look through this presentation. MIT Libraries recent cancellation of a service because of its use of DRM is also an interesting data point in the ongoing DRM debate.
I'm told that eventually there will be a podcast of the ALPSP event available so you'll be able to listen to all the talks and get the context and discussion not available from the slides alone.
posted by Leigh Dodds at 11:08 am
![]()
![]()
Publishing 2.0 Conference 25th April
This one day conference lines-up a number of acknowledged experts drawn from the publishing and XML standards worlds, and will focus on how some publishers are deriving benefits from innovation, as well as what up-coming technologies and standards are likely to be making an impact in the near future.
I'm going to be giving a talk on RDF; how we're using it to model academic publications; and why we think its going to deliver advantages. The full line-up is pretty impressive, and includes a keynote from Sean McGrath who is an excellent speaker.
I'm very pleased to have been invited to speak at the event. And as an un-reformed geek how could I turn down the opportunity to speak at Bletchley Park?!
Check the event page for registration details.
posted by Leigh Dodds at 10:48 am
![]()
![]()
Science Blogging, Blog Carnivals and Secondary Publishing
Wednesday, March 28, 2007
The experience was an education in not only writing to a schedule, but also a great introduction to a wide range of XML technologies and some pretty arcane markup lore. The process was also largely an editorial one; over time I think I got pretty good at picking out key contributors and relating topics across different forums. It was also pretty intensive as there was a lot of information to absorb and summarize.
Having gained this first hand experience at taking technical topics and opening them up to a wider audience, Blog Carnivals have interested me for some time. Blog Carnivals attempt to provide a weekly or monthly summary of key postings in a particular blogging community or topic. The source media is different (blogs versus mailing lists) but the editorial process and end results are essentially the same: a regular digest of important scholarly or technical discussions. Carole Anne Meyer has described Blog Carnivals as secondary publishing reinvented.
There's a growing number of high quality Blog Carnivals produced by scholarly communities. See for example this list of science carnivals which includes Bio::Blogs and Tangled Bank.
Ben Vershbow has described these scholarly carnivals as a "looser, less formal peer review" process. Vershbow went on to explain that "the idea of the carnival, refined and sharpened by academics and lifelong learners, might in fact have broader application for electronic publishing. It happily incorporates the de-centralized nature of the web, thriving through collaborative labor, and yet it retains the primacy of individual voices and editorial sensibilities".
So I was intrigued to read in Nautilus this week that the Bio::Blogs carnival has started producing a monthly compilation of the best bioinformatics articles in PDF format. The content is distributed using Box.net free online storage to actually host the content. This is another step closer to a traditional secondary publishing model; Carnivals are becoming more and more like traditional publications all the time.
Some publishers may feel threatened by this, but academic blogging is a useful complement to scholarly journals, not a replacement. They're different kinds of media, often with a different audience, and certainly with a different "voice".
If you're interested to learn more about science blogging and other new forms of interaction, there's an opportunity for you to hear presentations from Ben Vershbow, and Sandra Porter (science blogger and Tangled Bank contributor) at the International Scholarly Communications Conference which I'm chairing on the 13th April.
Labels: web2.0 blogging
posted by Leigh Dodds at 2:15 pm
![]()
![]()
Persistent Links in Bookmarks
However, I've since decided that my proposed implementation is wrong! Originally I suggested embedding the link in a
META tag in the HTML. But it's dawned on me that the LINK tag is obviously a better alternative. The LINK tag is intended to be used to convey relationships between documents, and that's essentially what we're trying to achieve. There's even a predefined link type for indicating bookmark links.This mechanism is already in use on many blogs to identify the "permalink" for a specific article, e.g:
<a href="...some...url" rel="bookmark" title="Permalink">Permalink</a>.
So I'm going to revise my proposal so that persistent links to academic articles, e.g. DOIs, are embedded into web pages by adding a
LINK tag into the HEAD of the document as follows:
<link rel="bookmark" title="DOI" href="http://dx.doi.org/10.1000/1"/>
The system is extensible as we can agree a convention, similar to RSS auto-discovery that the combination of the
rel and title attributes convey information about the type of link. For example to include both a stable DOI link and a direct link to the current publisher's website, we could use the following:
<link rel="bookmark" title="DOI" href="http://dx.doi.org/10.1000/1"/>
<link rel="bookmark" title="Publisher" href="http://www.doi.org/index.html"/>
User agents (e.g. bookmarklets and other tools) and social bookmarking sites can then offer the user a choice of which link to use (to avoid security issues) or simply store both.
Labelling DOIs like this also enables them to be more easily extracted for other purposes. We're already including DOIs, expressed as info: URIs, in our embedded Dublin Core metadata, but the actual web link is useful too (if not more so!)
Thoughts?
posted by Leigh Dodds at 11:37 am
![]()
![]()
bioGUID
bioGUID is an attempt to provide "resolvable URIs for biological objects, such as publications, taxonomic names, nucleotide sequences, and specimens".
The system currently supports DOIs, PubMed identifiers, Handles, and GenBank sequences amongst other identifier schemes. Under the hood all the information is available as RDF. Linking to, for example, an organism we can find related links, bookmark the organism on del.icio.us, and view its location on a map.
Collections of identifiers like bioGUID will become key jumping off points in the growing web of data. These "linking hubs" will provide navigational aids to both humans and machines; tieing distributed data sets and collections into a larger hypertext system will have numerous benefits, not least of which will be making it easier to find stuff.
Web 2.0 is really the collective realization that it's the humble link that is the powerhouse of the internet.
Labels: "institutional identifier", bioGUID, identifiers, RDF
posted by Leigh Dodds at 10:51 am
![]()
![]()
The Machine is Us/ing Us
The video is by Michael Wesch, assistant professor of cultural anthropology at Kansas State University. Its a great visual introduction to some Web 2.0 and markup concepts. You can read more about the video here. Wesch has explained that his aim was to "show people how digital technology has evolved and give them a sense of where it might be going and to give some momentum to the all-important conversation about the consequences of that on our global society."
Labels: web2.0 video
posted by Leigh Dodds at 9:22 am
![]()
![]()
eye/to/eye: our latest publisher newsletter just mailed
- our appointment of Leigh Dodds as Ingenta CTO
- further news on our merger with VISTA
- an overview of institutional registry and identifier models, following OCLC's recent announcement that it has thrown its hat into this ring
- review of our Publisher Forum, held in December and addressing issues relating to "Information Industry Vectors: where next for technology & business models"
- review of our Open Forum, held in February - a discussion themed around "Reaching out to customers directly: improving the way you market your content"
- news of the latest publishers to join the IngentaConnect service
Labels: "information industry", "institutional identifier", "institutional registry"
posted by Charlie Rapple at 9:21 am
![]()
![]()
Academic Journals as a Virtual File System
Tuesday, March 20, 2007
WebDAV is an extension to HTTP that provides facilities for distributed authoring and versioning of documents. The protocol is natively supported on both the Windows and Mac desktops thereby allowing direct access, publishing and authoring of content held in remote repositories in a seamless way. To the end user the repository looks exactly like a network drive and they can use normal file management options to manage documents.
After reading a blog posting from Jon Udell yesterday and in particular the notion of WebDAV proxies and virtual documents, I got to wondering about where else WebDAV could be applied.
Central to WebDAV is the a notion of a hierarchy of documents, each of which can have its own metadata. Sounds very much like the typical browse path for academic journals to me: titles, issues, articles.
So what if we were to expose journals as a "virtual file system" using WebDAV? A user could then integrate a journal (or collection of journals) directly into their file-system. Accessing content would be as simple as browsing through directories (i.e. an issue) to find the relevant content (e.g. a PDF file, HTML file, etc).
Obviously access control is an issue here. Arbitrary users wouldn't be edit documents, so the file system would be read-only. And, apart from Open Access titles, not everyone would necessarily be authorized to access the full-text of all content within a journal. But that's OK too; a WebDAV server doesn't have to expose a real file-system. What's exposed can be a virtual collection of content and that content can be limited to just those journals, issues, and articles to which the user has access. In a similar fashion the WebDAV proxy could also ensure that usage statistics are accurately recorded.
There's other options too, e.g. for publishing and sharing related research data, supplementary information, etc. Authorized users (the publisher, author, editors) could add the related information directly into the WebDAV file-system.
It seems to me that this could be a pretty powerful technique. It would provide a simple, familiar metaphor for accessing journal content. And users wouldn't need to accumulate and organize local copies of PDFs (and they do!). Instead they would be able to mount the content from any networked computer.
The are some obvious downsides. There's no search option, no sophisticated browsing, etc. Viewing journals as a virtual file system of content is certainly not right for all users or usage patterns. But one thing that Web 2.0 has taught us is that supporting a flexible range of access options is an important criteria.
The idea speaks directly to a wider debate about how academic publishers could or should disseminate content in the future. Assuming the correct access controls are in place and the content metadata is easily and widely available, do publishers really need to more than expose their content in these kinds of ways? Instead leaving end users and intermediaries to add value?
Labels: filesystem, http, pdf, WebDAV
posted by Leigh Dodds at 9:59 am
![]()
![]()
ASA event : “Policies, Pricing and Purchasing”
Wednesday, March 14, 2007
IngentaConnect recently made it down to the Association of Subscription Agents and Intermediaries’ event “Policies, Pricing and Purchasing” in
DAY ONE
Does the journal have a price any longer?
John Cox, Managing Director, John Cox Associates
- Dominant model remains electronic free with print.
- A number of publishers are pricing by size of institution – by number of sites, FTE, JISC banding, Carnegie classification, even (still) simultaneous users.
- Publishers will then often sub-set pricing by market, geographic region, academic or corporate, number of members.
- Some publishers now differentiating pricing by service level, charging more for a more extensive service.
- ¾ of publishers offer articles on a pay-per-view (PPV) basis. Most regard PPV as a significant line item in the profit and loss statement.
- Consortia pricing – dominant model remains ‘previous year plus’ or number of members. (i.e. what you pay in the current years is linked to what you paid in the previous year plus a percentage agreed/negotiated increase). Consortia tend to seek price caps as a way of managing budget mid-term.
Pricing the package
Nick Evans, Members Services Manager, ALPSP and Tamsyn Honour, Swets Information Services UK
- Publishers package content: to maintain revenue
- A review of available content in the market place reveals 250,000 publications, 2m pricing options.
- Packaging helps librarians make purchasing easier.
- Packages range from 4.9 million GBP in price down to less than 20GBP
- Often, scale of operations will help publishers successfully engage the market. For example, Elsevier have 100 staff involved in consortia negotiation ongoing – smaller publishers cannot resource this.
Business models that work
Ian Snowley, Director, Academic Services, University of London Research Library Services, and President-Elect the Chartered Institute of Library and Information Professionals (CILIP)
1700 libraries were surveyed:
- How many of your subscriptions are electronic? 26-90% range, average 70%
- How many expected to be electronic in 10 years? 75-100% range, 90% average
- 100% of libraries purchase print + electronic subscriptions
- 85% participate in purchases on the big deal model
- Librarians are strongly in favour of longer term trials from publishers, as it is the only way that they can reasonably gauge and cost-justify investment in subscription.
- Libraries are purchasing print + electronic but then pulping the accompanying print journal to avoid the VAT burden of going e-only
- Is open access going to make a difference to library budgets? 50% said no, 50% said don’t know
DAY TWO
Intermediation in the new user environment
Chris Beckett, Director, Scholarly Information Strategies Ltd
- Initially publishers created their own sites and silo’d content. New intermediaries have emerged – Google, A&I services, etc. To a large degree, these intermediaries overcome the “problem” of silos.
- Users are increasingly bypassing the onsite navigation and silos of the major publishers’ sites. Instead they are taken directly to the article (or abstract) through search engines, A&I services, etc. With this in mind, publishers need to consider article level branding (i.e. within the PDF). Providing high quality metadata is vital in order to be found.
- Instead of lots of publisher platforms with their own features and layouts, publishers should consider using online journal platforms (such as IngentaConnect) so that users have one easily understood, familiar environment in which to find what they are looking for.
- Use of Web 2.0 tools will become the more effective way to find information.
Discovery - empowering the user
Kate Stanfield, Head of Knowledge Management, CMS Cameron McKenna LLP
- Libraries want better statistics and a single search interface for multiple sources, clear easy access with silent authentication “Just make your content findable and give it to us – that’s all we care about”.
- They favour publishers/services that integrate easily into their library portal.
Where are consortia heading? 1. The
Paul Harwood, Director, Content Complete
- Online services originally came with the promise of rapid, easy access to the content to which you subscribe. This promise is not always kept. Institutions are extremely frustrated when they cannot access their content. We should be delivering on the original promise of online access.
posted by EdMcLean at 11:18 am
![]()
![]()
Top CiteULike tags for IngentaConnect articles
Friday, March 09, 2007
Richard Cameron has obligingly created this for us, and so now you can view a tag cloud for IngentaConnect articles tagged on CiteULike. Thanks to Richard for providing this so quickly.
The cloud makes for interesting reading, and it'd be interested to compare (or amalgamate) the data with that of different services, e.g. Connotea. Its also going to be interesting to compare these figures with our usage statistics; some content on the site gets much more activity than others. I suspect there may be audience differences between, e.g. general users of IngentaConnect and those that also use social bookmarking tools.
posted by Leigh Dodds at 12:51 pm
![]()
![]()
Grazr
Thursday, March 08, 2007
Today's example is going to use Grazr a service that amongst its various features, allows you to build a little customized RSS viewer for linking to or embedding in your own applications.
Its pretty easy to do:
Firstly, visit the Grazr Create a Widget page. You'll be prompted with a simple three step process:
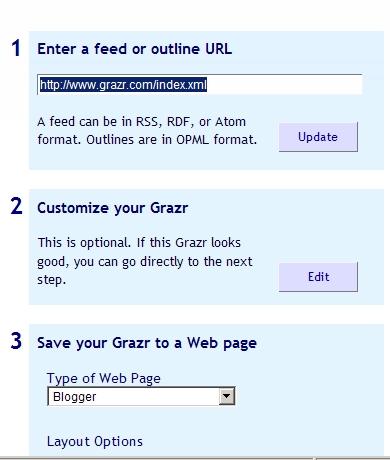
As I've just written a posting about OPML exports lets create a widget for exploring the table of contents data for our Medical titles.
This is the URL we need. Size limits on the widget restrict the numbers of titles it'll import in one go, so that link only contains the first 200 titles. Copy and paste that into the box provided in Step 1, and click "Update". After a few seconds your widget should be showing a list of titles.
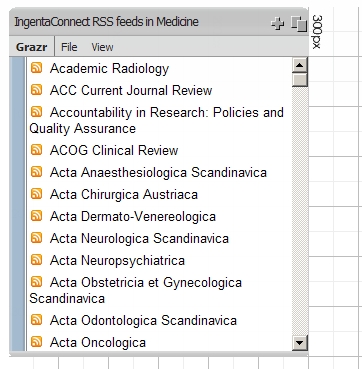
In Step 2 we choose a colour scheme, fonts, and sizing. I decided to try the the "
sateen_green" theme. Here's how it looks: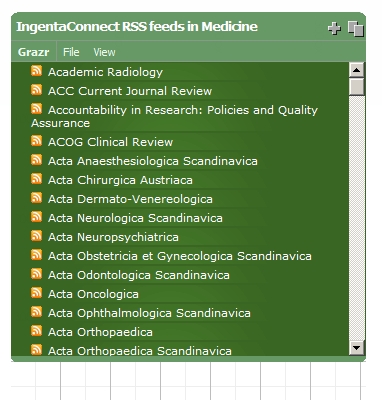
Finally, we decide to publish. For the purposes of this article, lets use the little grazr icon:

And we're done. Click on the icon, and you can view the widget for yourself. Selecting a title will pull in the latest list of articles, and you can then click through to read the abstract (or download the full text) on IngentaConnect.
posted by Leigh Dodds at 4:13 pm
![]()
![]()
OPML Exports from IngentaConnect
The feeds are embedded in the subject category pages using an "auto discovery" link similar to that used for RSS feeds, e.g:
<link
rel="index"
type="application/xml"
title="OPML" href="http://api.ingentaconnect.com/content/subject?j_pagesize=-1&format=opml&j_subject=142" />
The URLs could be tidier, but they do the job. I thought I'd publish a list of the feeds here:
- Agriculture/Food Sciences
- Arts and Humanities
- Biology/Life Sciences
- Chemistry
- Computer and Information Sciences
- Earth and Environmental Sciences
- Economics and Business
- Engineering/Technology
- Mathematics and Statistics
- Medicine
- Nursing
- Philosophy/Linguistics
- Physics/Astronomy
- Psychology/Psychiatry
- Social Sciences
Using those links should get you listing of the main IngentaConnect RSS feeds for our electronic collection (i.e. the latest title feed for each journal), grouped by our subject categories. Useful if you're interested in subscribing to a bunch of feeds in one go, or grabbing lists of RSS feeds to create a directory.
Only interested in the feeds for titles that your institution has a subscription to? Then we support that too. At present it relies on IP authentication to identify you and your institution, so its only useful if you're accessing the link from on campus, or via a proxy server, and obviously that your institution has subscriptions activated on IngentaConnect.
To subset the list, add the following parameter to any of the URLs:
&j_availability=subs
Thats it.
Any problems or suggestions for improvements, please let me know.
posted by Leigh Dodds at 2:42 pm
![]()
![]()
Table of Contents by Really Simple Syndication
The project write-up goes into more details and provides links to some sample RSS feeds and a (yet to be populated) Sourceforge project which will be home to some of the code developed during the prototype.
While the experiment was no doubt worthwhile, I think the project is something of a missed opportunity, as it failed to take into account any of the existing work thats been done on enriching publication feeds with detailed metadata.
For example Nature, Ingenta, and other publishers have been producing RSS feeds containing rich metadata for several years now. Collectively we've converged on RSS 1.0 supplemented with Dublin Core and PRISM metadata to carry precisely the information added to the TOCRoSS feeds, only using RSS 2.0 and ONIX. You can compare and contrast examples.
The existing formats have already been successfully used to drive other services, e.g. CiteULike, so there's demonstrable implementation experience that suggests that they meet a number of use cases.
While there's certainly plenty of room for debate about which format(s) and vocabularies are better -- perhaps Atom should replace all of them? -- its a shame that the project didn't focus on drawing out the existing lessons learnt and areas for further work.
Also, had the project adopted existing formats then the code that will ultimately be published would also have been much more useful: it would immediately work with thousands of existing feeds, as opposed to requiring publishers to support another variant format.
posted by Leigh Dodds at 2:00 pm
![]()
![]()
Task Force on “Development of OECD statistical products”
Wednesday, March 07, 2007
The documentation for that meeting including my presentation is now available online.
The meeting included representatives from the OECD and from a number of national statistics organizations. It was interesting to learn about their challenges in publishing statistics and discuss their plans to reach a mixture of audiences both expert and otherwise. For my part I provided an overview of Web 2.0 and discussed the increasingly diverse range of lightweight publishing options that are available. I showed some demos of tools like Exhibit, Google Spreadsheets, Many Eyes, Swivel, and other data visualization examples using tools like Google Maps and Google Earth. We also discussed the potential for Semantic Web technologies in this space.
I suggested that the arrival of a "YouTube for data" isn't far away. Indeed tools like Swivel are aiming to deliver just that. Data publishing and visualization is a topic thats of increasing interest to a wide range of publishers.
Declan Butler has a short piece in Nature that reviews this latest trend. Armin Grossenbacher, another OECD task force attendee, maintains a blog about dissemination of official statistics which also has some useful pointers and commentary.
posted by Leigh Dodds at 5:10 pm
![]()
![]()
Persistent linking, web crawlers and social bookmarking
Where a site has access controlled content and the full-text resides at a different location, this presents a problem. The site owner or publisher would like users to go to one page, e.g. the abstract, but will want the crawler to get the full-text. Making this work involves some dialogue between site owner and the search engine. For example the web crawler needs to use an alternate index or additional metadata to make the connection between the index entry link and the full-text retrieval link.
Some site operators, with approval, use a technique known as "cloaking" to achieve this. This involves serving different content to a web crawler, e.g. a PDF, than would be served to an end user, e.g. an abstract. Most search engines disapprove of this approach, but Google Scholar, for example has allowed it. This has caused some debate.
On IngentaConnect we use cloaking to serve content to some crawlers. But we no longer do this for Google Scholar. The reason for this is that Google were interested in obtaining the richer metadata that we include (as embedded Dublin Core) in abstract pages. This metadata, supplemented with the full-text, improves the quality of Scholar search indexes.
I thought I'd explain the fairly simple solution I concocted to achieve this and point out where the same technique could be used to improve another problem: persistent linking in social bookmarking services.
When the Googlebot requests an abstract page from IngentaConnect, it gets fed some additional metadata that looks like this:
<meta rel="schema.CRAWLER" href="http://labs.ingenta.com/2006/06/16/crawler"/>
<meta name="CRAWLER.fullTextLink" content=""/>
<meta name="CRAWLER.indexEntryLink" content=""/>
The embedded metadata provides two properties. The first,
CRAWLER.fullTextLink, indicates to the crawler where it can retrieve the full-text that corresponds to this article.The second link,
CRAWLER.indexEntryLink, indicates to the crawler the URL that it should use in its indexes. I.e. the URL to which users should be sent. The technique is fairly simple and uses existing extensibility in HTML to good effect. It occured to me recently that the same technique could be used to address a related problem.
When I use del.icio.us, CiteULike, or Connotea or other social bookmarking service, I end up bookmarking the URL of the site I'm currently using. Its this specific URL that goes into their database and associated with user-assigned tags, etc.
However, as we all know, in an academic publishing environment content may be available on multiple platforms. Content also frequently moves between platforms. The industry solution to this has been to use the DOI as a stable linking syntax. Some sites like CiteULike make attempts to extract DOIs from bookmarked pages, or resolve DOIs via CrossRef. But the metadata they collect is still typically associated with the primary URL and not the stable identifier. This presents something of a problem if, say, one wants to collate tagging information across services, or ensure that links I make now will still work in the future.
A more generally applicable approach to addressing this issue, one that is not specific to academic publishing, would be to include, in each article page, embedded metadata that indicates the preferred bookmark link. The DOI could again be pressed into service as the preferred bookmarking link. E.g.
<meta rel="schema.BOOKMARK" href="http://labs.ingenta.com/2007/03/7/bookmark"/>
<meta name="BOOKMARK.bookmarkLink" content="http://dx.doi.org/10.1000/1"/>
This is simple to deploy. It'd also be simple to extend existing bookmarking tools to support this without requiring specific updates from the owners of social bookmarking sites. If the tool found this embedded link it could use it, at the option of the user, instead of the current URL.
The only downside I can see to this is the potential for abuse: it could be used to substitute links to an entirely different site and/or content for that which the user actually wants to bookmark. This is why I think users ought to be given the option to use the link, rather than silently substituting it. If owners of sites like CiteULike or Connotea decided to support this crude "microformat" then they can easily deploy a simple trust metric, e.g. that they'll use this metadata from known and approved sites.
I'd be interested in feedback on this as its something that we'll likely deploy on IngentaConnect in the next few weeks.
posted by Leigh Dodds at 3:41 pm
![]()
![]()
Scribd
A recent addition to these micro-publishing sites is Scribd which describes itself as "a free online library where anyone can upload". The Scribd FAQ suggests that Scribd could be used for publishing "serious academic articles".
The site certainly has some interesting features which are of interest to an academic publishing environment, although the content itself is currently pretty variable in quality! As such, its another useful data point in the ongoing discussion of how academic publishing could evolve.
Amongst the features that I found particularly interesting are its use of FlashPaper to embed a PDF style viewer directly into web pages; the ability to download content in multiple formats, including MP3; the text and traffic analysis; and the integration with Print(fu), a separate service that allows purchasing of printed copies of PDFs.
posted by Leigh Dodds at 3:02 pm
![]()
![]()
