
Creating new content on IngentaConnect. The quick and easy way
Monday, September 25, 2006
I have spent the last couple of weeks developing the new tools and navigation bar for IngentaConnect. Leigh's recent post covers our reasons for making all these changes very thoroughly. It was down to me to implement them.
I use the Ingenta templating system every day but the speed at which I was able to create the new content needed amazed me. I was able to create other display formats such as print, BibText and EndNote for pages by simply adding a parameter and creating a new template file for each page with the right name, the templating system takes care of the rest.
Similarly adding things like OpenURL links to the page was a matter of finding the information available to a given page and working out how that fits into the OpenURL format.
All this relatively easy development let me concentrate on the layout and functionality of the interface. Right from the start it was obvious there was going to be too much information to comfortably fit into the limited space of the right hand column on the site. I needed to come up with a method that allowed the user to quickly find the information that they need without too many mouse clicks and without resorting to “hunting and pecking” to borrow a typing term.
The solution was to only show the heading for the various sections of the navigation bar and have sections expand to reveal more content when the user clicks on the section heading. This is fairly easy to do with JavaScript and many sites take a similar approach.
I always make accessibility a priority when developing interfaces so it was also important that the new interface would work with JavaScript turned off. This meant that I had to jump through a few more hoops. If you turn off JavaScript in your browser and visit the site you will see all of the content in the navigation column is visible. When JavaScript is running it hides the additional content and changes the section headings for content that has been hidden into links to show hidden content when the page loads. This makes the JavaScript as unobtrusive as possible.
The templating system makes working with JavaScript a breeze too. It is possible to include a JavaScript file at any level from the entire site to an individual page by adding a single line to the file that drives the whole templating system. This makes it easy to have the same HTML mark up on all pages in the site for things like the sign in form but use the templating system to include a file with the JavaScript code in it to activate the collapsing behaviour in certain sections.
After templating, HTML and JavaScript the other missing element to my side of the work is CSS. Again its possible to include CSS files at many levels within the site using a properties file. The whole hiding content was only possible using CSS as it is possible to declare something as “display: none” to hide it entirely. This would not be possible by using HTML and JavaScript alone.
Having a system that was designed from the ground up to make working with the core elements of the presentation layer of a site as easy as possible means that it is possible to concentrate on how all these elements work together in creating an interface for the client. The implementation becomes almost secondary to the functionality.
I use the Ingenta templating system every day but the speed at which I was able to create the new content needed amazed me. I was able to create other display formats such as print, BibText and EndNote for pages by simply adding a parameter and creating a new template file for each page with the right name, the templating system takes care of the rest.
Similarly adding things like OpenURL links to the page was a matter of finding the information available to a given page and working out how that fits into the OpenURL format.
All this relatively easy development let me concentrate on the layout and functionality of the interface. Right from the start it was obvious there was going to be too much information to comfortably fit into the limited space of the right hand column on the site. I needed to come up with a method that allowed the user to quickly find the information that they need without too many mouse clicks and without resorting to “hunting and pecking” to borrow a typing term.
The solution was to only show the heading for the various sections of the navigation bar and have sections expand to reveal more content when the user clicks on the section heading. This is fairly easy to do with JavaScript and many sites take a similar approach.
I always make accessibility a priority when developing interfaces so it was also important that the new interface would work with JavaScript turned off. This meant that I had to jump through a few more hoops. If you turn off JavaScript in your browser and visit the site you will see all of the content in the navigation column is visible. When JavaScript is running it hides the additional content and changes the section headings for content that has been hidden into links to show hidden content when the page loads. This makes the JavaScript as unobtrusive as possible.
The templating system makes working with JavaScript a breeze too. It is possible to include a JavaScript file at any level from the entire site to an individual page by adding a single line to the file that drives the whole templating system. This makes it easy to have the same HTML mark up on all pages in the site for things like the sign in form but use the templating system to include a file with the JavaScript code in it to activate the collapsing behaviour in certain sections.
After templating, HTML and JavaScript the other missing element to my side of the work is CSS. Again its possible to include CSS files at many levels within the site using a properties file. The whole hiding content was only possible using CSS as it is possible to declare something as “display: none” to hide it entirely. This would not be possible by using HTML and JavaScript alone.
Having a system that was designed from the ground up to make working with the core elements of the presentation layer of a site as easy as possible means that it is possible to concentrate on how all these elements work together in creating an interface for the client. The implementation becomes almost secondary to the functionality.
posted by Rob Cornelius at 11:04 am
![]()
![]()
Refining the Article Page
Wednesday, September 20, 2006
In his presentation at SSP's annual meeting Roy Tennant noted the increasing importance of the article page on STM websites, explaining to publishers that "Most users of your content will never see your home page...they don't want to learn how to use your site, nor should they have to...your brand identity has to be at article level". You can read my write-up of the rest of the SSP conference for summary of other related presentations.
We've been monitoring this trend for a while. We've observed increased Google referrals directly to the article level as a result of our ongoing efforts to make IngentaConnect as search engine friendly as possible. While I'm sure that many publishers and hosting providers are aware of this increased traffic, not many have appreciated the important underlying point: i.e. that web sites need to adapt to this change in behaviour.
In the article-based view of the world it's very easy to lose sight of the fact that the article doesn't stand alone. It's part of an edited, managed resource: the journal. Increasing the level of journal branding can help promote this, perhaps drawing the user's attention to the fact that there may be other relevant and related content nearby.
But it's not all about branding; the functionality is also vital. Tennant observed that users don't want to learn a particular site's quirks. They're unlikely to navigate around and thereby stumble across other potentially useful site features. For example, while many sites offer alerting services, how many of them offer sign-ups direct from the article? Or, how many offer the ability to sign up for RSS feeds? Some sites do offer these options at article level, but it's far from consistent.
There are other features that would typically be presented to the user on the journal homepage (subscription activation, subscription purchase options, etc) that are also increasingly important to offer at the article level. The information architecture of a typical academic journal website assumes a user browsing "down" to content, visiting useful information at the journal, table of contents, and ultimately the article level along the way. But this view needs to be turned on its head. The article has become the predominant resource and one needs to draw the user "up" towards other relevant features. Or, better yet, simply offer them directly at the article level.
Avoiding the need to navigate away from the article drives a design towards offering all useful tools, e.g. bookmarking, linking, citation manager exporting, directly on the article page. This avoids the need for the user to navigate away from the content of interest, but there is obviously a trade-off between increasing the utility and branding of the article page and cluttering up the page with too many options.
In the next week or so we're releasing some updates to content and search sections of IngentaConnect that attempt to adapt the site navigation options to meet the changing needs of users. The effects will be most marked on the article page, where the user will be presented with a rich set of tools covering all of the above functionality. There will also be some increased journal branding.
We've tried to make the pages dynamic to allow users to access the new options through expanding/collapsing sections of the navigation bar, avoiding too much page clutter. I'd be very interested to hear comments on how well we've achieved this in practice.
There will be some new features included too. For example, the options to export data to citation managers have been expanded, with EndNote and Bibtext options appearing at all levels. Autodiscovery links for RSS will also appear everywhere, making it quick and easy to sign-up to RSS feeds from any content page. With increasing browser support for RSS autodiscovery, this can now be a single-click operation.
At the recent data webs conference, Ben Lund noted the problems he's encountered when attempting to reliably extract metadata from publishers sites for integration into connotea. To help address this, the revised content pages will also include auto-discovery links for BibText and EndNote along with the RSS links. Use of these links isn't limited to social bookmarking. In fact, coupled with the embedded Dublin Core metadata we're already sharing to good effect, there should now be easy access to metadata in a variety of formats, using a variety of methods. Enough for many different kinds of usage. (Let me know if you've got additional requirements)
I'm also pleased that we've been able to add in direct links to several social bookmarking services including del.icio.us and connotea (of course). So you can quickly bookmark, tag, and share articles direct from the page itself.
There are more features to come, but we'd like to get feedback on these initial changes before plowing on further. Once the changes are live I'll follow up with a more technical posting discussing some of the metadata export options.
We've been monitoring this trend for a while. We've observed increased Google referrals directly to the article level as a result of our ongoing efforts to make IngentaConnect as search engine friendly as possible. While I'm sure that many publishers and hosting providers are aware of this increased traffic, not many have appreciated the important underlying point: i.e. that web sites need to adapt to this change in behaviour.
In the article-based view of the world it's very easy to lose sight of the fact that the article doesn't stand alone. It's part of an edited, managed resource: the journal. Increasing the level of journal branding can help promote this, perhaps drawing the user's attention to the fact that there may be other relevant and related content nearby.
But it's not all about branding; the functionality is also vital. Tennant observed that users don't want to learn a particular site's quirks. They're unlikely to navigate around and thereby stumble across other potentially useful site features. For example, while many sites offer alerting services, how many of them offer sign-ups direct from the article? Or, how many offer the ability to sign up for RSS feeds? Some sites do offer these options at article level, but it's far from consistent.
There are other features that would typically be presented to the user on the journal homepage (subscription activation, subscription purchase options, etc) that are also increasingly important to offer at the article level. The information architecture of a typical academic journal website assumes a user browsing "down" to content, visiting useful information at the journal, table of contents, and ultimately the article level along the way. But this view needs to be turned on its head. The article has become the predominant resource and one needs to draw the user "up" towards other relevant features. Or, better yet, simply offer them directly at the article level.
Avoiding the need to navigate away from the article drives a design towards offering all useful tools, e.g. bookmarking, linking, citation manager exporting, directly on the article page. This avoids the need for the user to navigate away from the content of interest, but there is obviously a trade-off between increasing the utility and branding of the article page and cluttering up the page with too many options.
In the next week or so we're releasing some updates to content and search sections of IngentaConnect that attempt to adapt the site navigation options to meet the changing needs of users. The effects will be most marked on the article page, where the user will be presented with a rich set of tools covering all of the above functionality. There will also be some increased journal branding.
We've tried to make the pages dynamic to allow users to access the new options through expanding/collapsing sections of the navigation bar, avoiding too much page clutter. I'd be very interested to hear comments on how well we've achieved this in practice.
There will be some new features included too. For example, the options to export data to citation managers have been expanded, with EndNote and Bibtext options appearing at all levels. Autodiscovery links for RSS will also appear everywhere, making it quick and easy to sign-up to RSS feeds from any content page. With increasing browser support for RSS autodiscovery, this can now be a single-click operation.
At the recent data webs conference, Ben Lund noted the problems he's encountered when attempting to reliably extract metadata from publishers sites for integration into connotea. To help address this, the revised content pages will also include auto-discovery links for BibText and EndNote along with the RSS links. Use of these links isn't limited to social bookmarking. In fact, coupled with the embedded Dublin Core metadata we're already sharing to good effect, there should now be easy access to metadata in a variety of formats, using a variety of methods. Enough for many different kinds of usage. (Let me know if you've got additional requirements)
I'm also pleased that we've been able to add in direct links to several social bookmarking services including del.icio.us and connotea (of course). So you can quickly bookmark, tag, and share articles direct from the page itself.
There are more features to come, but we'd like to get feedback on these initial changes before plowing on further. Once the changes are live I'll follow up with a more technical posting discussing some of the metadata export options.
posted by Leigh Dodds at 9:37 am
![]()
![]()
More Merging with SPARQL
Tuesday, September 12, 2006
Last week, I queried a scruffy little RDB with SPARQL, using SquirrelRDF.
This week, with a bit of help from the Jena team, I've been merging data across sources, where one is the shiny new triplestore, and one the scruffyLittleRDB.
I wanted to write a query to tell us where we've sent a particular article header, and when. (We push data off to Crossref, Ebsco, etc etc.)
To answer this question, I needed:
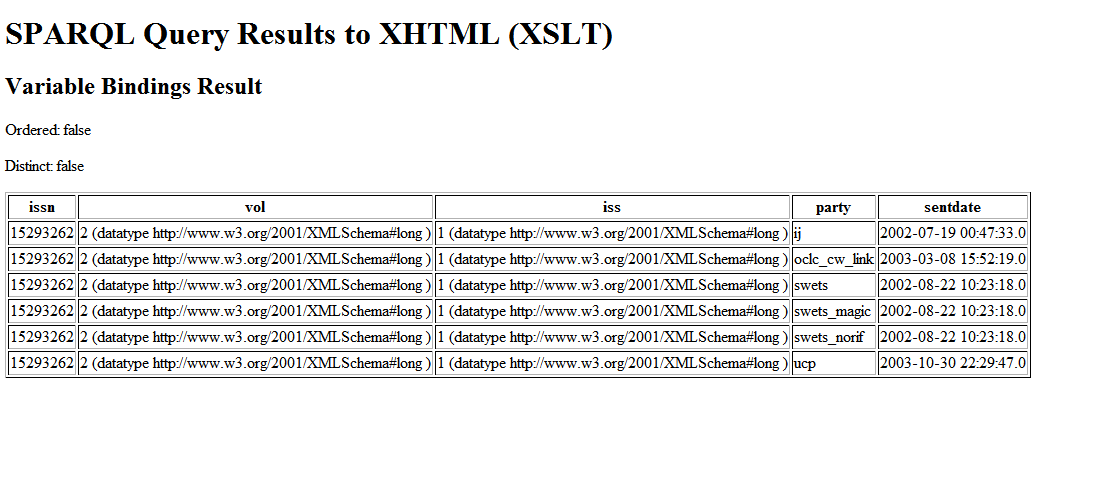
1. Literal data about articles from the big triplestore. I picked on article /333333. As you can see, it was published in volume 33, number 4, of the Journal "Behavior Research Methods, Instruments, & Computers".
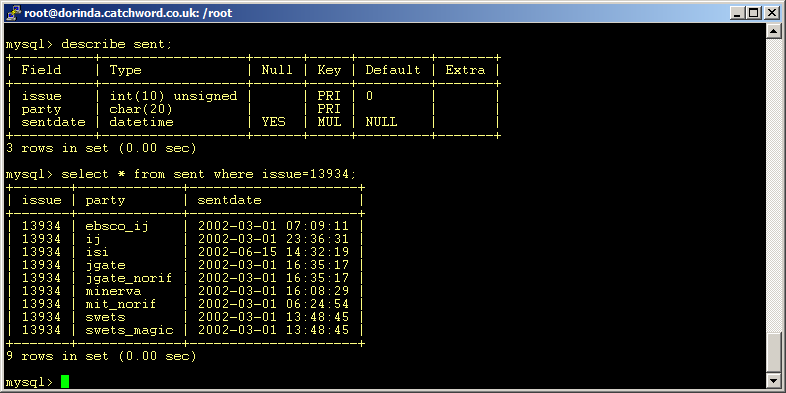
2. Who-which-where data from the distribution database. It also has a notion of journals and issues - this issue is the same one as my 'article 333333' above belongs to. It also knows who we've sent that issue to, and when.
I extended my SPARQL Service to allow named models which are actually (known) SquirrelRDF sources.
Here's my query, (or a screenshot of it anyway):
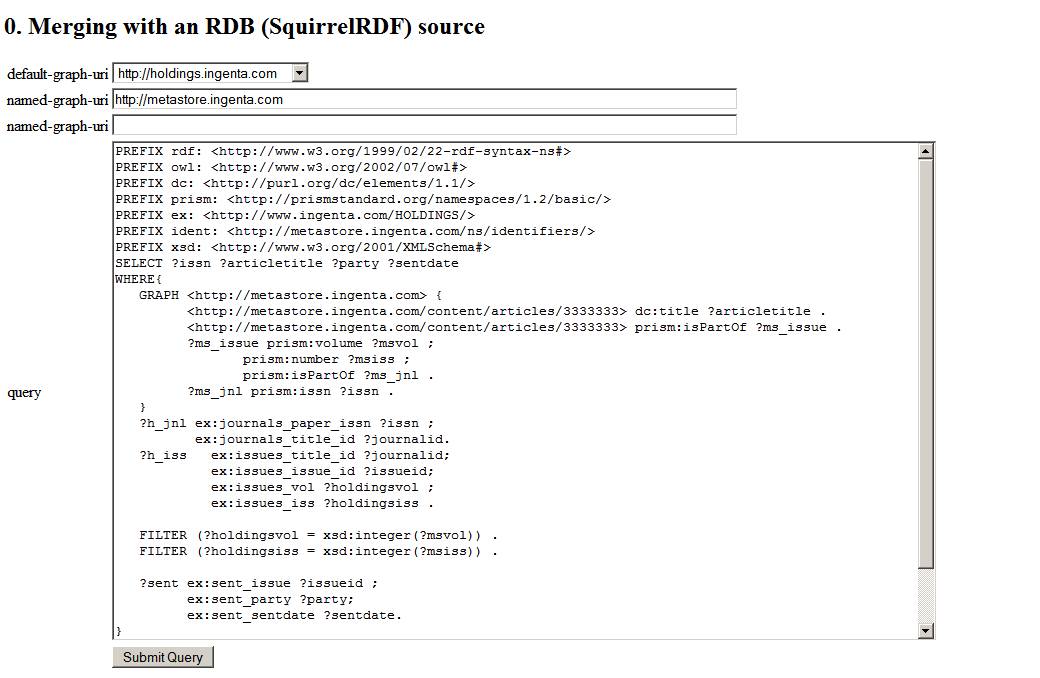
(Scared yet?)
And here are the results.
I promised to report my findings as I went along, so this was my experience with this latest experiment ...
1. Merging is all very dependent on finding suitable identifiers on which to join.
If you look at the query , you'll see I'm identifying an article by the ISSN of the journal it is from, the journal volume, and the journal issue. I'm joining on all three to get some identity between the two sources. This makes for a complex query. But there are no other options, (or none I can think of!) The scruffyLittleRDB has its own identifier system.. the traditional autoincrementing field. The triplestore, no matter how clever, can never guess these identifiers - and so we are reduced to poking around with literals. Things get even nastier when you consider datatypes - note I'm translating with a FILTER.
2. SPARQL can get quite fierce.
SPARQL Queries can be a bit - well, big! Writing real-world SPARQL reminds me of writing regexes; I start itching to comment every line. I've scared two SQL engineers away from my screen with that one above already!
As ever, more to come..
This week, with a bit of help from the Jena team, I've been merging data across sources, where one is the shiny new triplestore, and one the scruffyLittleRDB.
I wanted to write a query to tell us where we've sent a particular article header, and when. (We push data off to Crossref, Ebsco, etc etc.)
To answer this question, I needed:
1. Literal data about articles from the big triplestore. I picked on article /333333. As you can see, it was published in volume 33, number 4, of the Journal "Behavior Research Methods, Instruments, & Computers".
2. Who-which-where data from the distribution database. It also has a notion of journals and issues - this issue is the same one as my 'article 333333' above belongs to. It also knows who we've sent that issue to, and when.
I extended my SPARQL Service to allow named models which are actually (known) SquirrelRDF sources.
Here's my query, (or a screenshot of it anyway):
(Scared yet?)
And here are the results.
I promised to report my findings as I went along, so this was my experience with this latest experiment ...
1. Merging is all very dependent on finding suitable identifiers on which to join.
If you look at the query , you'll see I'm identifying an article by the ISSN of the journal it is from, the journal volume, and the journal issue. I'm joining on all three to get some identity between the two sources. This makes for a complex query. But there are no other options, (or none I can think of!) The scruffyLittleRDB has its own identifier system.. the traditional autoincrementing field. The triplestore, no matter how clever, can never guess these identifiers - and so we are reduced to poking around with literals. Things get even nastier when you consider datatypes - note I'm translating with a FILTER.
2. SPARQL can get quite fierce.
SPARQL Queries can be a bit - well, big! Writing real-world SPARQL reminds me of writing regexes; I start itching to comment every line. I've scared two SQL engineers away from my screen with that one above already!
As ever, more to come..
posted by Katie Portwin at 3:40 pm
![]()
![]()
How does a scruffy little RDB get into a Triplestores-Only Golf Club?
Thursday, September 07, 2006
This week, I've been playing with SquirrelRDF. It allows you to query RDBs with SPARQL. Magic.
Why? Well, there are lots of RDBs full of interesting metadata, lurking under rocks here at Ingenta. It's my job to worry about integrating metadata, and for us, the future is RDF.
I could tip ALL the data into my nice new triplestore. All your databases will be ASSSIMILATED. Resistance is futile, etc etc. And that's probably the way to go with most of it.
But in some cases, this approach just isn't appropriate. What if the owner guards it jealously and I'm waiting for them to go on leave before we snaffle it? What if the data is itself a bit freaky, and I just don't want it polluting my store? What if I haven't written the loader yet. (Writing loaders is a lot of work!) What if there's just butt-loads of it, so the load is going to take 6 weeks of processing? I want that data NOW!
I decided to experiment with SquirrelRDF (Although D2RQ would be another option.) It implements this spec, and works by treating each row as a resource, where the column names are its properties, and the column values are the objects.
Eg:
I have a database called POND, and in it, a table called FROGS which goes
_x ns:FROGS_ID 1
_x ns:FROGS_name "Fred"
_x ns:FROGS_colour "green"
_x ns:FROGS_legs 4
_y ns:FROGS_ID 2
...etc..
Where "ns" is some URI I configure - eg http://www.ingenta.com/POND/
One nice advantage is I don't have to define a new vocabulary for Frogs - that's all automatic, based on the db schema.
Overall, it was a good out-of-the box experience. I downloaded the jars, and ran a command line utility which generated this maping file. It seemed to handle the datatypes OK, and made the automatic vocabulary. Next, I was able to run a SPARQL query using another command line utility. Finally, I installed the little webapp, and did the same thing over HTTP; I entered this query in the box, and got these results.
Of course, it won't be able to offer the flexibility of a real RDF store - it will still be a faff to add a new property etc. But, at least I should be able to do SPARQL on it, and start joining it up with other data from the triplestore, or from under other rocks.
Why? Well, there are lots of RDBs full of interesting metadata, lurking under rocks here at Ingenta. It's my job to worry about integrating metadata, and for us, the future is RDF.
I could tip ALL the data into my nice new triplestore. All your databases will be ASSSIMILATED. Resistance is futile, etc etc. And that's probably the way to go with most of it.
But in some cases, this approach just isn't appropriate. What if the owner guards it jealously and I'm waiting for them to go on leave before we snaffle it? What if the data is itself a bit freaky, and I just don't want it polluting my store? What if I haven't written the loader yet. (Writing loaders is a lot of work!) What if there's just butt-loads of it, so the load is going to take 6 weeks of processing? I want that data NOW!
I decided to experiment with SquirrelRDF (Although D2RQ would be another option.) It implements this spec, and works by treating each row as a resource, where the column names are its properties, and the column values are the objects.
Eg:
I have a database called POND, and in it, a table called FROGS which goes
This gets translated to triples:
ID | name | colour | legs
----------------------------
1 | Fred | green | 4
2 | Felix | yellow | 4
3 | Frank | green | 3
_x ns:FROGS_ID 1
_x ns:FROGS_name "Fred"
_x ns:FROGS_colour "green"
_x ns:FROGS_legs 4
_y ns:FROGS_ID 2
...etc..
Where "ns" is some URI I configure - eg http://www.ingenta.com/POND/
One nice advantage is I don't have to define a new vocabulary for Frogs - that's all automatic, based on the db schema.
Overall, it was a good out-of-the box experience. I downloaded the jars, and ran a command line utility which generated this maping file. It seemed to handle the datatypes OK, and made the automatic vocabulary. Next, I was able to run a SPARQL query using another command line utility. Finally, I installed the little webapp, and did the same thing over HTTP; I entered this query in the box, and got these results.
Of course, it won't be able to offer the flexibility of a real RDF store - it will still be a faff to add a new property etc. But, at least I should be able to do SPARQL on it, and start joining it up with other data from the triplestore, or from under other rocks.
posted by Katie Portwin at 10:00 am
![]()
![]()

{kind=link}
{kind=link}
{kind=link}
{kind=link}