
More Merging with SPARQL
Tuesday, September 12, 2006
Last week, I queried a scruffy little RDB with SPARQL, using SquirrelRDF.
This week, with a bit of help from the Jena team, I've been merging data across sources, where one is the shiny new triplestore, and one the scruffyLittleRDB.
I wanted to write a query to tell us where we've sent a particular article header, and when. (We push data off to Crossref, Ebsco, etc etc.)
To answer this question, I needed:
1. Literal data about articles from the big triplestore. I picked on article /333333. As you can see, it was published in volume 33, number 4, of the Journal "Behavior Research Methods, Instruments, & Computers".
2. Who-which-where data from the distribution database. It also has a notion of journals and issues - this issue is the same one as my 'article 333333' above belongs to. It also knows who we've sent that issue to, and when.
I extended my SPARQL Service to allow named models which are actually (known) SquirrelRDF sources.
Here's my query, (or a screenshot of it anyway):
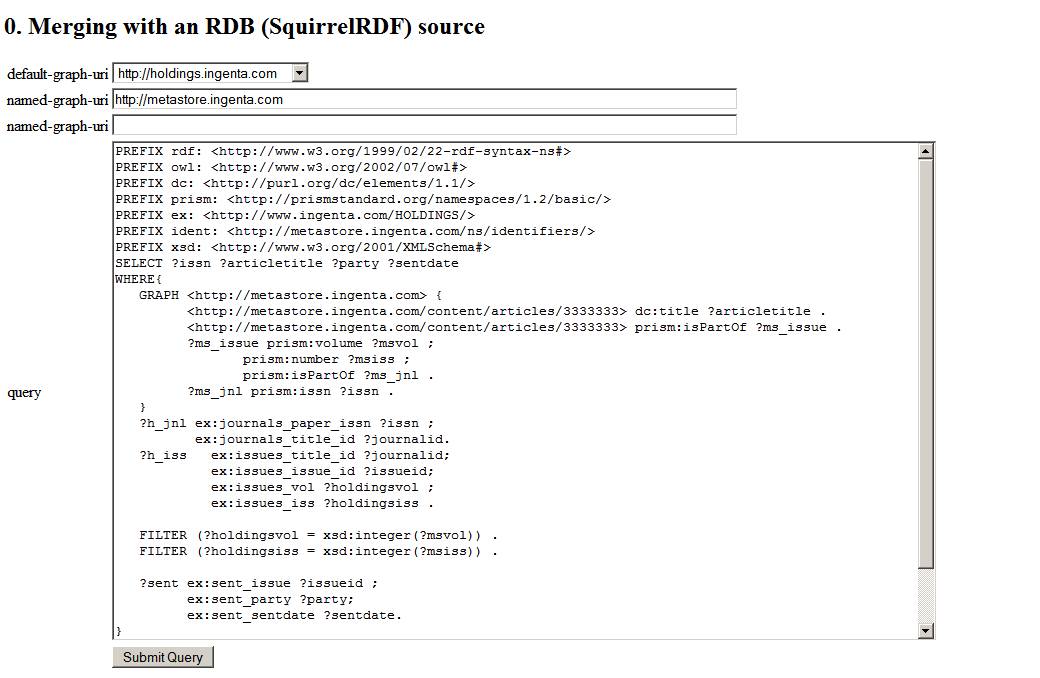
(Scared yet?)
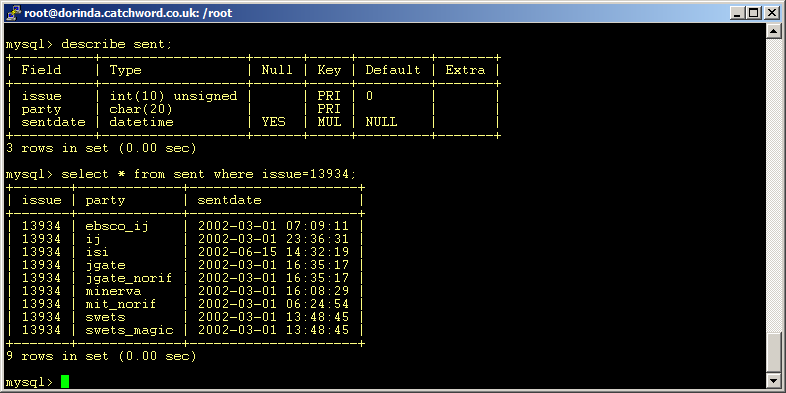
And here are the results.
I promised to report my findings as I went along, so this was my experience with this latest experiment ...
1. Merging is all very dependent on finding suitable identifiers on which to join.
If you look at the query , you'll see I'm identifying an article by the ISSN of the journal it is from, the journal volume, and the journal issue. I'm joining on all three to get some identity between the two sources. This makes for a complex query. But there are no other options, (or none I can think of!) The scruffyLittleRDB has its own identifier system.. the traditional autoincrementing field. The triplestore, no matter how clever, can never guess these identifiers - and so we are reduced to poking around with literals. Things get even nastier when you consider datatypes - note I'm translating with a FILTER.
2. SPARQL can get quite fierce.
SPARQL Queries can be a bit - well, big! Writing real-world SPARQL reminds me of writing regexes; I start itching to comment every line. I've scared two SQL engineers away from my screen with that one above already!
As ever, more to come..
This week, with a bit of help from the Jena team, I've been merging data across sources, where one is the shiny new triplestore, and one the scruffyLittleRDB.
I wanted to write a query to tell us where we've sent a particular article header, and when. (We push data off to Crossref, Ebsco, etc etc.)
To answer this question, I needed:
1. Literal data about articles from the big triplestore. I picked on article /333333. As you can see, it was published in volume 33, number 4, of the Journal "Behavior Research Methods, Instruments, & Computers".
2. Who-which-where data from the distribution database. It also has a notion of journals and issues - this issue is the same one as my 'article 333333' above belongs to. It also knows who we've sent that issue to, and when.
I extended my SPARQL Service to allow named models which are actually (known) SquirrelRDF sources.
Here's my query, (or a screenshot of it anyway):
(Scared yet?)
And here are the results.
I promised to report my findings as I went along, so this was my experience with this latest experiment ...
1. Merging is all very dependent on finding suitable identifiers on which to join.
If you look at the query , you'll see I'm identifying an article by the ISSN of the journal it is from, the journal volume, and the journal issue. I'm joining on all three to get some identity between the two sources. This makes for a complex query. But there are no other options, (or none I can think of!) The scruffyLittleRDB has its own identifier system.. the traditional autoincrementing field. The triplestore, no matter how clever, can never guess these identifiers - and so we are reduced to poking around with literals. Things get even nastier when you consider datatypes - note I'm translating with a FILTER.
2. SPARQL can get quite fierce.
SPARQL Queries can be a bit - well, big! Writing real-world SPARQL reminds me of writing regexes; I start itching to comment every line. I've scared two SQL engineers away from my screen with that one above already!
As ever, more to come..
posted by Katie Portwin at 3:40 pm
![]()
![]()

{kind=link}
{kind=link}
<<Blog Home