
Ingenta launches pub2web
Friday, November 23, 2007
For immediate release
27th November 2007
Ingenta launches pub2web
Next generation publications platform is best-of-breed solution to evolving publisher and user needs
Ingenta, the technology provider that connects the publishing and information industries, today announces the launch of its next generation publications platform, pub2web. This full-service feature-rich publishing system assembles best-of-breed components into a scalable, extensible platform, building on the proven technical architecture of leading research destination IngentaConnect while offering comprehensive customisation options to its clients. [More about the system's architecture] Publishers will benefit from fully-tailored graphical design, flexible information and content architecture, and an extensive suite of functionality that ranges from standard website navigation tools, to leading-edge features that take advantage of evolving browser capabilities.
pub2web is also fully integrated with the company's award-winning Metastore, a data repository designed to support flexible content types, multiple search and browse options and semantic data mining. It goes beyond the restrictive infrastructure of paper journals to support innovative online business models, while greatly reducing content loading times, allowing content to be accessible online within minutes of upload. [More about Metastore] Meanwhile, the platform's state-of-the-art search functionality offers enhanced indexing of author names, spell checking, additional sorting options and relevance rankings. [More about pub2web searching]
Launch clients for the new platform include the World Bank, which will deploy pub2web to upgrade its e-Library, the International Monetary Fund and the Organisation for Economic Co-operation and Development (OECD), which has selected pub2web to deliver the third generation of its prestigious online library SourceOECD. OECD's Head of Publishing, Toby Green, explains why:
"In 2000, Ingenta built our first-generation service, offering our journals, books, reference works and interactive databases in a single, seamless, website. At that time, combining such an array of different content types into a single, seamless, site was considered innovative. Now, we must continue to innovate with tools and services that increase our users' productivity and we think Ingenta's pub2web platform will allow us to do just that. Our third-generation service using pub2web will launch in mid-2008. It’s an exciting time."
"The loyalty of major clients like the OECD, IMF and World Bank is one of the critical success factors in any service organisation," comments Ingenta Vice President Douglas Wright. "I'm pleased that we can justify their commitment to us with a robust new publication platform to showcase their increasingly complex range of content. pub2web exemplifies our pro-active, dynamic approach to technology, giving publishers the control they seek and enabling us to compete very convincingly in the online publishing sector."
To find out more about our pub2web publications platform, please visit the Publishing Technology stand (404) at Online Information. Alternatively, download this PDF.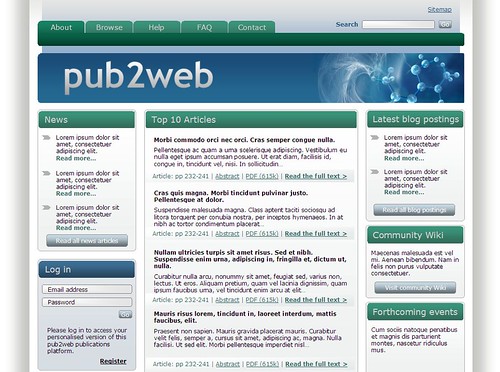
Example design for the homepage of a pub2web publications platform;
features include data feeds of news and top articles, integration of blogs and wikis,
along with more traditional features such as browse and search navigation,
access control, and help documentation.
pub2web's technical architecture is a multi-tier Java J2EE application running on the open source JBoss application server and the Jetty servlet engine. The system is backed by a mixture of database technologies including Oracle, Postgres and MySQL. Web services conforming to the REST architectural pattern are used to bring together data in real-time for creating a dynamic user experience for end users. Agile software engineering practices and rigorous release processes will allow rapid installation and deployment of a continuous stream of application upgrade, allowing Publishing Technology to deliver modular developments and ensure each client’s pub2web platform remains state-of-the-art. [back to main body]
pub2web's Metastore data repository is an RDF (Resource Description Framework) triplestore, built using Jena, an open source Java framework developed by Hewlett Packard's HP Labs. RDF provides a framework for describing resources, their metadata and their relationships. "Resources" could simply be academic papers, but the technology is flexible enough to represent any kind of research data that a publisher might wish to deliver through pub2web. [back to main body]
pub2web's search engine is powered by Open Source codebases Solr, an enterprise search server, and Lucene, a highly respected search engine library used by several applications and websites including Wikipedia. Its flexible architecture can index any file from which text can be extracted, enabling it to catalogue the many data types deliverable by a pub2web site. [back to main body]
ENDS
For more information, please contact:
Charlie Rapple
Ingenta, a division of Publishing Technology
Tel: +44 1865 397860
Email: charlie.rapple@publishingtechnology.com
MSN: rappleland@hotmail.com
AIM: Rappleland
RSS feed of Publishing Technology's news releases
Ingenta's All My Eye blog
About Ingenta
www.ingenta.com
Ingenta is the global market leader in online management and distribution of publications, allowing publishers to focus on their core business by outsourcing their online publishing requirements. Ingenta's key competences include website design and development, data conversion and enhancement, secure online hosting, access & authentication and content discoverability management. Flagship web platform IngentaConnect provides 250 research publishers and societies with a ready-made audience (of over 20,000 libraries) for their publications. For libraries and information professionals, the site offers comprehensive collection management and document delivery options for over 30,000 publications. Ingenta also develops and maintains discrete publication websites, and delivers a range of complementary technology services including Information Commerce Software, which provides flexible infrastructure and tools to enable publishers to repackage, bundle or price content online at the click of a button.
In 2007, Ingenta merged with VISTA International to form Publishing Technology plc, the largest provider of publishing software solutions. The company is listed on the AIM market of the London Stock Exchange and has offices in Europe and North America.
Labels: books, databases, electronic publishing, journals, pub2web, publications platform, RDF, reference works, search engine
posted by Charlie Rapple at 12:06 pm
![]()
![]()
Open Data in the Social Sciences
Saturday, November 10, 2007
Open data wasn't invented yesterday: The Roper Center for public access to polling data opened in 1946. ICPSR founded in 1962. Research data sharing really took off in '60s with census data, major surveys, etc. In social sciences, large number of students & faculty build career on public data. This was made possible, in part, due to post-war and 1960s increase in funding for the social sciences.
"Putting People on the Map" report from National Academies of Science. How do we make sure social data is shared, public protected, public investment reaps value?
Social sciences benefit from the DDI Metadata Standard which defines an XML standard for open data sharing within social sciences.
What do you mean by data? Traditionally: closed-end survey results. Increasingly though questions are data? Actually this is a more "normal" way to approach the literative for a social scientist. Qualitative data? Video & Audio?
Minding our Knitting (or what social scientists can't lose focus on):
- curation matters
- The scientific authority of ICPSR is critical, and is established by reports that mention ICPSR as key infrastructure
- must protect the human subjects of research who are the basis of studies
What are the imperatives/challenges?
- Financial. Open data doesn't mean free data. Who owns the data? Costs of curation and preservation. Different funding models for data (e.g. membership, subscription, sponsorship)
- Protecting Confidentiality. All of the most interesting data has the potential for use in identifying individuals.
- Maintaining Provenance and Authority
"Preservation related transformations" must preserver provenance.
Open data is reality in social science.
Labels: "charleston conference", "open data", "social sciences"
posted by Leigh Dodds at 2:44 am
![]()
![]()
Open Access: Good for Society, Bad for Libraries?
Anderson suggested that Open Access would threaten library budgets, reducing the funding available to the library. Plutchak referred to the "cognitive dissonance" resulting from, on one hand, librarians being exhorted to promote and encourage OA, while on the other the disruptive changes that may follow if that is successful.
Plutchak characterized this by saying that "the myth we're all fighting" when defending library budgets is that "it's all available for free on the internet", while "the future we're trying to create" is one where "it's all available for free on the internet".
Both speakers promoted a broader view of library activities and an understanding of the core values underpinning what libraries do. Plutchak described those core values
as providing access for all; enabling preservation; and promoting literacy. In Plutchak's view, to continue to promote literacy, librarians need to move from thinking about training users in "how to use the resources in our library" to an emphasis on "how to use resources on the internet".
Anderson also spoke about the continuing need for librarian involvement in information access and the greater need for "discrimination" amongst online resources.
Anderson described three potential new roles for librarians:
- Moving from being brokers to publishers, e.g. through institutional repositories
- Contributing to managing local archives and data services, e.g. curating institutional research data sets.
- Participating in creating virtual journals that tailor information resources for their patrons
Interestingly both speakers strongly recommended librarians look to Peter Morville's book, "Ambient Findability" as a source of inspiration for the future role of librarians.
Labels: "open access" library2.0
posted by Leigh Dodds at 2:39 am
![]()
![]()
Clifford Lynch Keynote at Charleston
Thursday, November 08, 2007
Lynch opened by describing the need to take an expanded view of the scholarly literature, suggesting that forthcoming changes in how the literature is used and accessed with put strain on a number of arrangements within the industry, including areas such as service delivery, licensing, etc.
Lynch's main topic was the growing board of research and effort that surrounds computational access to the scholarly literature; in short analysing scholarly papers using text and data mining techniques. Lynch suggested that Google's PageRank was an early example of the power of this kind of analysis, and proposed that the time is very ripe for additional computational exploration of scientific texts. Lynch noted that the life sciences are particularly active in this area at the moment, largely because of the large commercial pay-offs in mining life science literature (think pharmaceutical industry).
When research conduct this research they often want to combine public literature with private research data (used as "leverage on the literature"), mixing it with other useful data sources, such as thesauri, geographical data, etc.
Lynch also noted that current content licensing agreements don't allow or support this kind of usage, and wondered how the legal and licensing frameworks needed to adapt to support it?
Lynch then moved on to discussing three key questions:
Firstly was "Where is the scientific corpus mined?". Lynch observed that there are "horrenous" problems with distributed computing scenarios, e.g. normalization, performance problems, cross-referencing and indexing across sites, and how to securely mix in private data.
Lynch felt that realistically (at least in near term), mining will be about computation on a local copy of the literature. How do we set things up so that people are able to do that? Lynch noted that institutions may need to consider their role in maintaining, building (and purging) these local copies of the literature. E.g. do they become owned and maintained as library services?
Lynch also noted that current hosting platforms don't make it easy to compile collections, although things are much easier with Open Access titles.
Lynch's second question was: "What is the legal status of text mining?". Lynch considered this to be a highly speculative area, with littel case law to draw on.
Lynch introduced the notion of "derivate works" under copyright law. Some derivatives can be mechanically produced (e.g. "first 5 pages"). Some derivatives, like translations involve some additional creativity. Summaries of works are not usually viewed as derivatives however, becoming the property of the summarizer. The current presumption, therefore, is that computationally produced content is derivative and so there are obvious issues for data mining.
Lynch suggested that we need to start being explicit about "making the world safe for text mining". By including special provisions in licenses for example.
As an aside, Lynch wondered what computation Google might be doing, or might be able to do, on the corpus its currently through various digitization efforts.
Lynch's third and final questions was "Do we need to change the nature of the literature to support computation?" E.g. by making it easier to analyze texts which are available as XML.
Lynch pointed to some useful underpinning thats are already under active research, e.g. efforts to analyze texts to identifying things, extracting references to people, places and organizations from the text. Lynch explained that these are major underpinning to more sophisticated analysis.
Adding microformats or subject specialist markup to documents would also help identify key entities in the text. Lynch wondered who would be responsible for doing this, the authors, or would it become a new value added service provided by publishers?
Labels: "charleston conference", "data mining"
posted by Leigh Dodds at 4:32 pm
![]()
![]()
See you in Charleston?
Friday, November 02, 2007
"Authoritative? What's that? And who says?"
Thursday Concurrent Session 1, 4.15-5pm, Rutledge Room, Francis Marion Hotel
Our Chief Technology Officer (and AME blogger) Leigh Dodds is teaming up with Laura Cohen of the University at Albany, SUNY (and Library 2.0 blogger) to explore what defines "authoritative" in the age of user-generated content, and to assess the respective benefits of both Web 2.0 technologies and traditional publishing processes such as peer review. Anyone who has seen Leigh speak will, I am sure, vouch for the high-quality of both his presentation style and subject matter, and in this case I think he's come up with another fascinating new perspective on the changes in scholarly publishing being wrought by new technologies.
"Publisher Consolidation: Where Does It Leave Us?"
Friday Lively Lunch, 12.15-1.45pm, Colonial Ballroom, Francis Marion Hotel
Janet Fisher, Senior Publishing Consultant at our sibling company PCG, will moderate a discussion led by Margaret Landesman of University of Utah Libraries and Diane Scott-Lichter of The Endocrine Society. They will explore the driving forces, repercussions and potential responses to ongoing consolidation within the publishing industry. Given how publishers seem endlessly to be merging with one another, I think this too will be a pretty pertinent panel.
"Best practices: improving librarian administration interfaces"
Friday Concurrent Session 1, 2-2.50pm, Pinckney Room, Francis Marion Hotel
Ingenta's Director of Library Services Claire Winthrop will participate in a panel discussion seeking ways to reduce the learning curve required for librarians to familiarise themselves with multiple publisher and vendor interfaces, and at the same time increasing the amount of control that librarians have over their users' interaction with content. This session will see representatives of the "big three" in scholarly content hosting all together on the same speaking platform for the first time - Claire will be sharing the stage with Atypon's Chris Beckett and Dan Tonkery of EBSCO (owners of Metapress) - so there is a real opportunity for collaborative progress to be made.
"Librarians, aggregators, and publishers: Can we all live together?"
Friday Concurrent Session 3, 4.15-5pm, Room 227, Addlestone Library, College of Charleston
Janet Fisher will take to the floor for a second time, joining with Todd Spires from Bradley University and Kate Duff from University of Chicago Press to explore the benefits of journal databases and consider whether librarians' purchasing choices allow aggregated databases to co-exist happily alongside publishers' other distribution channels. This issue has been widely debated in a number of fora but often without hard facts to underline the supposition, so the research underpinning this session should make for some evidence-based discussion at last.
If you're not going to make it to the event, then hopefully Leigh Dodds will be posting regular reports on its progress on this very blog.
Labels: "charleston conference", "librarian interfaces", "library administration", "peer review", "publisher consolidation", "web 2.0", aggregators, libraries, publishers
posted by Charlie Rapple at 11:31 am
![]()
![]()
